





低能耗、高效率
華碩 AI Accelerator PCIe 卡是第一款帶有多個 Coral Edge TPU 的 PCI Express® 擴充卡,用於邊緣 AI 推論。
華碩 AI Accelerator PCIe 卡是第一款帶有多個 Coral Edge TPU 的 PCI Express® 擴充卡,用於邊緣 AI 推論。
- 支援 AI 推論加速的 ASIC 設計
- 支援多個 AI 分析並行運行
- AI-model-pipelining技術實現低延遲
- 僅 36-52 瓦的低功耗
比較
低延遲平行 ML 推論
同時運作多個 AI 模型。
在需要執行多個模型的應用情境中,您可以將每個模型分配給一個特定的 Edge TPU 並加以平行執行,以達到最大效能。


採用模型管線處理技術,增強機器學習效能
對於需要快速反應或執行大型模型的應用,管線處理技術可將模型劃分為數個較小模型。
- 分區和執行:在不同的 Edge TPU 上執行較小的模型。
- 迅速反應 :提升高速應用中的吞吐量。
- 減少延遲:徹底減少大型模型的總延遲。
使用小型資料集,實現最佳 ML 結果
Edge TPU 主要適用於邊緣推論。 使用裝置端訓練功能,可透過預訓練模型執行 API 型傳輸學習功能,進而直接在 AI 加速器 PCIe 卡上實現微調模型。
- 提高模型準確度:透過 AI 加速器 PCIe 卡在邊緣實現遷移學習,無需伺服器/雲端互動,即可重新訓練模型。
- 節省訓練時間:使用不到 200 張影像即可優化模型,無需從頭開始。


享有事半功倍的出色效率
AI 加速器 PCIe 卡以能源效率為設計理念,具備出色的熱穩定性,可使用多個 Edge TPU 加快推論速度。
- 低功耗:36/52 W (8 到 16 個邊緣 TPU)。
- 無需外部 PSU:直接從 PCIe 插槽汲取電源。
設計 AI 應用程式原型,只需數分鐘即可完成
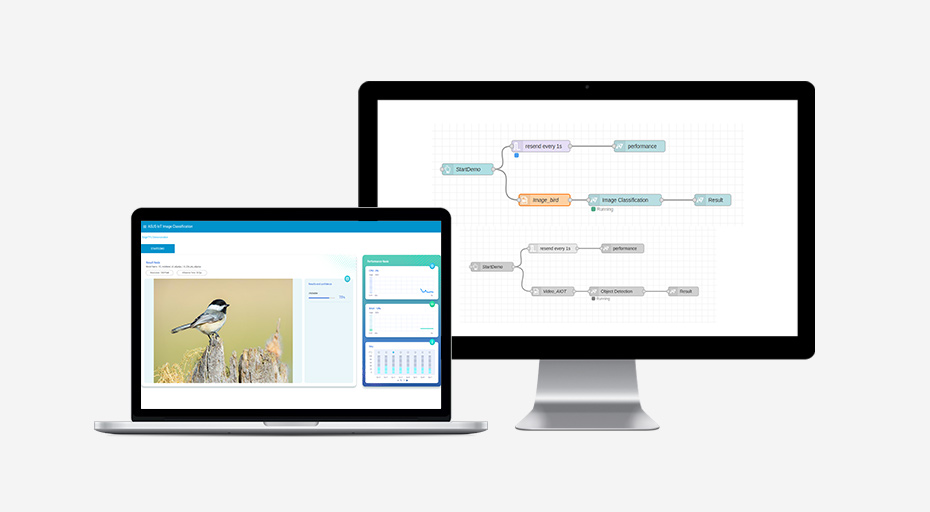
如需在短時間內構建 AI 演示或原型,AI 加速器 PCIe 卡可以隨時派上用場。我們開發了一款稱為 Edge TPU 推論節點的 AI 部署構建工具*,符合 Node-RED 規格。此編程工具支援使用 Edge TPU 節點輕鬆整合流程,只需點按一下即可 - 避免在原型設計階段進行繁瑣的編程工作。
- 直觀便利的平台:使用瀏覽器的圖形介面,無需進行編程。
- 簡單易用 :拖放並連接 ML 節點,即可完成部署。
- 資料視覺化:透過精美儀表板來監控 AI 加速器 PCIe 卡的使用指標。
*在此處下載 Edge TPU 推論節點
應用程式
-
製造

瑕疵偵測
公用事業監控
安全 -
零售業

店內自動結帳
人群密度分析
智慧看板 -
運輸

交通管理
車隊管理
停車 -
監視

侵入
虛擬圍欄
安全性
工作流程
ASUS AI 加速器 PCIe 卡如何部署 AI 模型
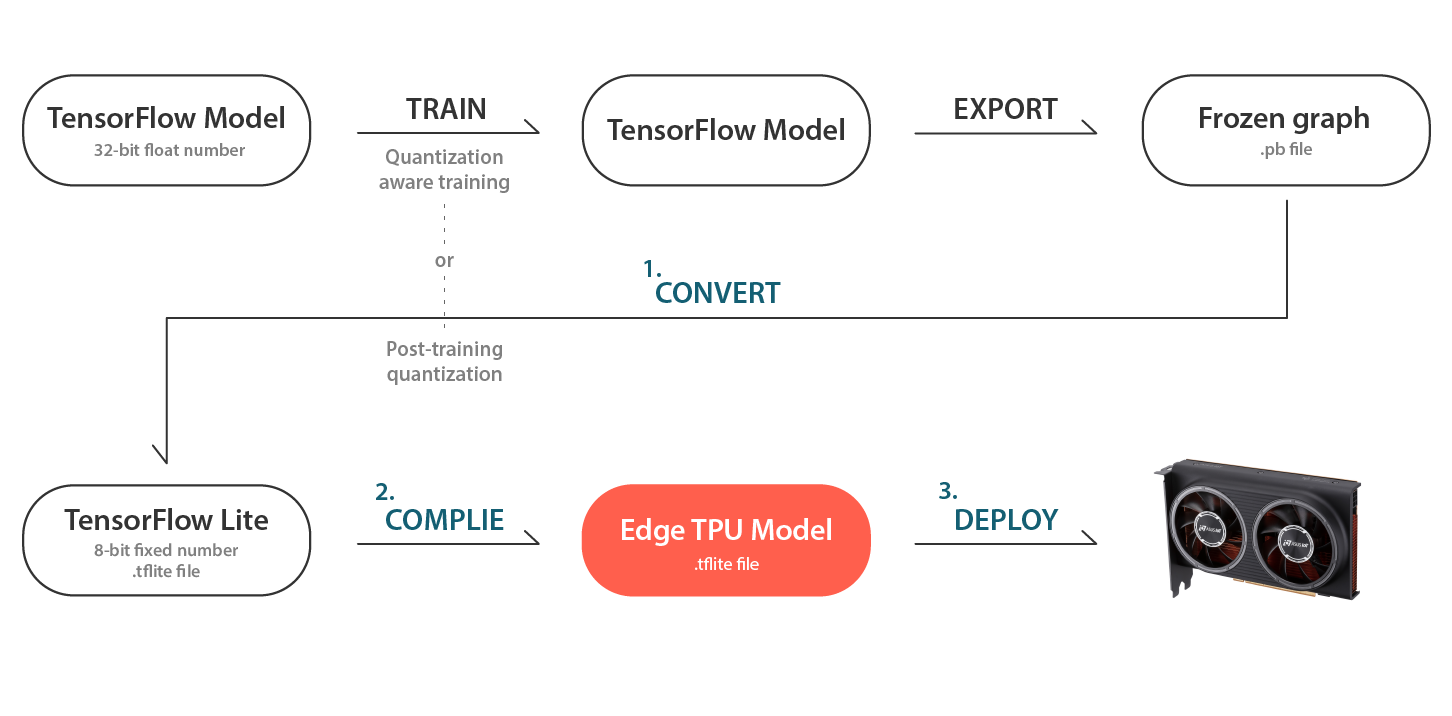
- TensorFlow Lite 轉換器:將 TensorFlow 模型 (含 .pb 副檔名) 轉換為 TensorFlow Lite 模型(含 .tflite副檔名)。
- 編譯器:一種命令列工具,可將 TensorFlow Lite 模型 (含 .tflite 副檔名) 編譯成為可在 Edge TPU 上執行的檔案。
- 部署 :透過 PyCoral API (Python) 或 Libcoral API (C++) 執行 AI 模型。
ML 模型要求
- ML 架構支援:TensorFlow Lite。
- 量化:已對張量參數進行量子化(8 位元定點數;int8)。
- 神經網路支援:卷積神經網路 (CNN)。
- 模型轉換:透過 TensorFlow 轉換器工具將 TensorFlow 模型轉換為 TensorFlow lite 模型。
技術規格

- ML 加速器:整合 8 到 16 個 Edge TPU,可實現 32 到 64 TOPS 效能
- 介面:PCI Express® (PCIe®) 3.0 x16
- 外型尺寸:全高、半長、雙槽寬
- 散熱:主動式風扇
- 作業溫度:0-55°C
- 尺寸:42.1 x 126.3 x 186.3 (寬 x 高 x 深 mm)
- 功耗:36 至 52 瓦特
- 支援的作業系統:Ubuntu 18.04、Debian 10 和 Window 10
訂購資訊
- CRL-G18U-P3D:整合 8 個 Edge TPU
- CRL-G116U-P3D:整合 16 個 Edge TPU












