





- Support up to 8~16 x Google® Coral Edge TPU M.2 modules
- Support TensorFlow Lite machine learning framework
- Compatible with PCI Express 3.0 x16 expansion slot
- Optimized thermal design with twin tuborfans
Parallel ML inferences with low latency
Run multiple AI models at the same time.


Enhance ML performance with model-pipelining technology
For applications that require fast response or large-model execution, pipelining techniques enable you to partition models into several smaller models.
- Partition and run : Execute smaller models on different Edge TPUs.
- Rapid response : Increase throughout in high-speed applications.
- Reduce latency : Minimize total latency for large models.
Maximize ML result with small datasets
The Edge TPU is primarily designed for inferencing at the edge. With on-device training, it’s possible to run API-based transfer-learning from a pre-trained model to achieve a fine-tuned model directly on the AI Accelerator PCIe Card.
- Increase model accuracy : Enable transfer learning at the edge via AI Accelerator PCIe card, with no need to for server/cloud interaction for model retraining.
- Save training time : Optimize models using fewer than 200 images, eliminating the need to start from scratch.


Do more with less energy
Designed with energy efficiency in mind, AI Accelerator PCIe Card is equipped with excellent thermal stability to achieve inference acceleration with multiple Edge TPUs.
- Low power consumption : 36/52 W ( 8/16 Edge TPUs).
- No external PSU needed : Power is drawn directly from the PCIe slot.
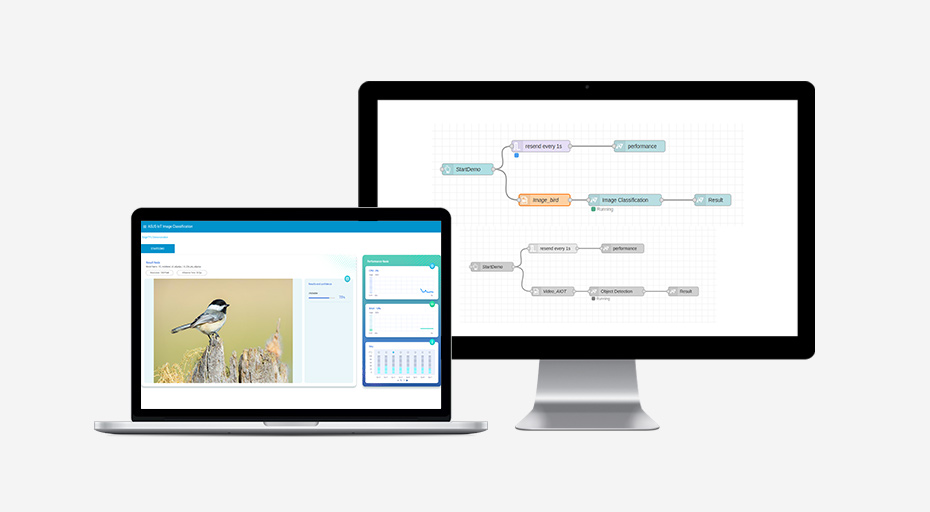
Prototype AI applications in minutes
If you have a need to build AI demonstrations or prototypes in short order then AI Accelerator PCIe Card is ready to help. We've developed an AI-deployment builder, called Edge TPU inference nodes*, in compliance with Node-RED. This programming tool enables flows to be wired together easily using the Edge TPU nodes, all with a single click – avoiding onerous coding during the prototyping stage.
- Intuitive platform : Browser-based with graphical interface, with no need for coding.
- Easy to use : Drag and drop any ML node, wire it up and it’s ready to deploy.
- Data visualization : Monitor usage metrics of the AI Accelerator PCIe Card via the beautifully-designed dashboard.
* Download Edge TPU inference nodes here
Applications
-
Manufacturing

Defect detection
Utilities monitoring
Safety -
Retail

In-store automated checkout
Crowd -density analysis
Intelligent signage -
Transportation

Traffic management
Fleet management
Parking -
Surveillance

Intrusion
Virtual fencing
Security
Workflow
How AI Models are deployed on ASUS AI Accelerator PCIe Card
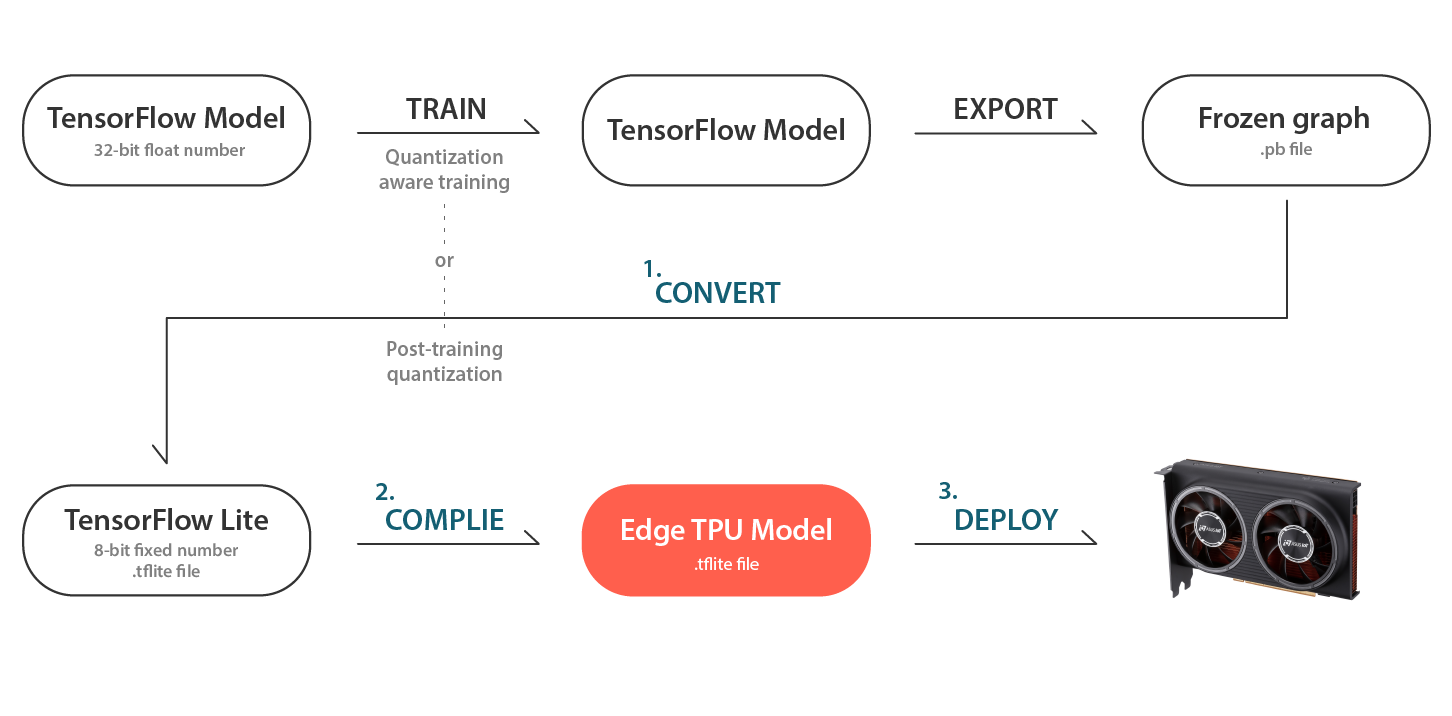
- TensorFlow Lite converter : Converts TensorFlow models (with .pb file extension) to TensorFlow Lite models (with .tflite file extension).
- Compiler : A command-line tool that compiles a TensorFlow Lite models (with .tflite file extension) into files that can be run on an Edge TPU.
- Deploy : To execute AI models via PyCoral API (Python) or Libcoral API (C++).
ML model requirement
- ML framework support : TensorFlow Lite.
- Quantization : Tensor parameters are quantized (8-bit fixed-point numbers; int8).
- Neural networks support : Convolutional Neural Networks (CNN).
- Model conversion : TensorFlow model to TensorFlow lite model via TensorFlow converter tool.
Technical specifications

- ML accelerator : Integrated with 8/16 Edge TPUs to achieve performance 32/64 TOPS
- Interface : PCI Express® (PCIe®) 3.0 x16
- Form factor : Full-height, half-length, double-slot width
- Cooling : Active fan
- Operating temperature : 0-55°C
- Dimensions : 42.1 x 126.3 x 186.3 ( W x H x D mm)
- Power consumption : 36 to 52 watts
- Supported operating systems : Ubuntu 18.04, Debian 10 and Windows 10
Ordering information
- CRL-G18U-P3D : Integrated with 8 Edge TPUs
- CRL-G116U-P3D : Integrated with 16 Edge TPUs





