


華碩 AI POD 包含 72 個 NVIDIA Blackwell GPU,每個 GPU 包含 2080 億個電晶體。 NVIDIA Blackwell GPU 都配備兩個具有光罩限制的晶粒,在一個GPU 中透過每秒 10 TB (TB/秒) 的晶片對晶片技術互連。

NVIDIA H100 Tensor Core GPU
H100
H100
CPU
與業界相比,華碩專注於打造客製化資料中心解決方案,並提供從混合式伺服器到邊緣運算部署的端到端服務。 我們不僅有硬體的優勢,我們還透過為企業提供軟體解決方案來加倍努力。 我們的軟體驅動引擎包括系統驗證和遠端部署,確保無縫操作以加速人工智慧開發。


NVIDIA NVLink 交換器具有 144 個端口,交換容量為 14.4 TB/s,允許 9 個交換器與單個 NVLink 域內 72 個 NVIDIA Blackwell GPU 上每個的 NVLink 連接埠互連。

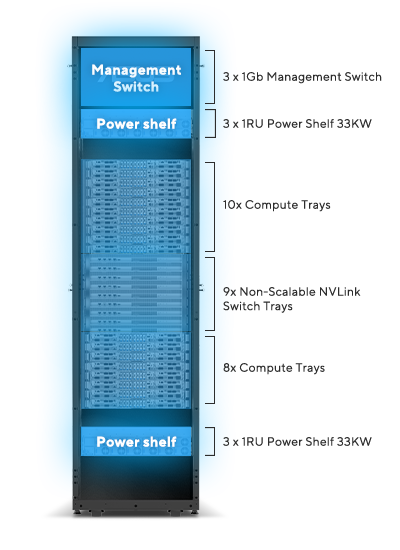
單一運算中的 NVLink 主動連線嘗試確保直接連線到所有 GPU

NVLink connectivity in single rack
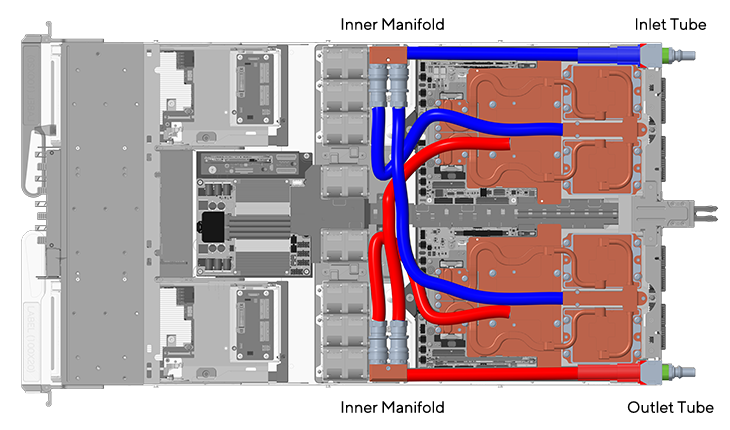
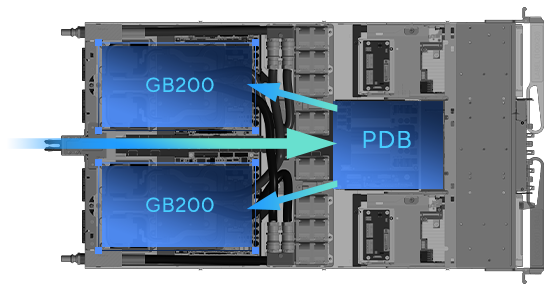
單一計算托盤中的熱水和冷水流動
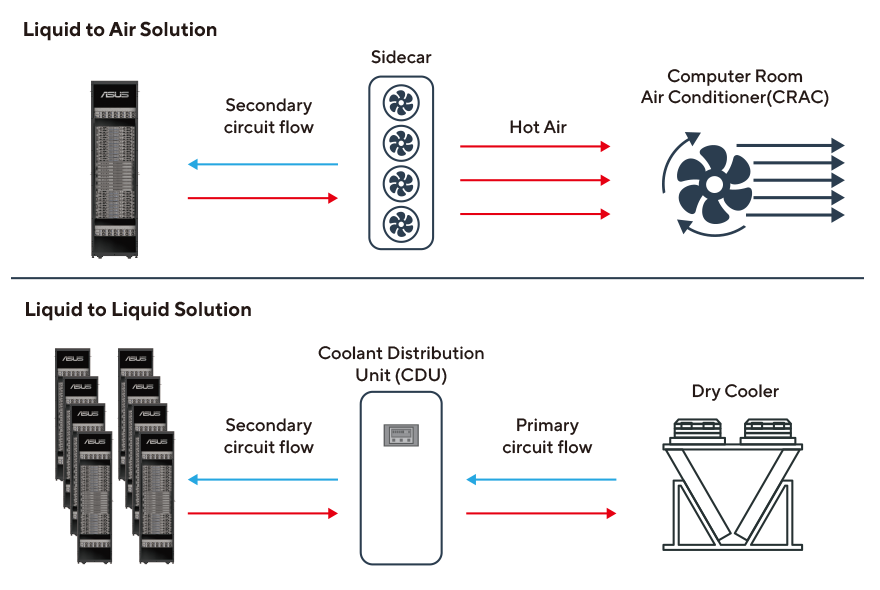
我們的解決方案優化了從華碩 AI POD 到整個資料中心,最後到冷卻水塔的冷卻效率,完成水循環。 我們提供液體到空氣或液體到液體冷卻解決方案的選擇,以確保有效散熱。
每個機架每年節省高達 1,000 美元的電費,以實現投資最大化和維護最小化
受益於溫度降低約 35°C
PDB 壽命顯著提高 11.3 倍